
Post-mortem: step processing backlogs on Aug 31, 2023
Tony Holdstock-Brown· 9/8/2023 · 6 min read
On Thursday 31 August at 7:06am PDT, we observed a backlog of steps processing, caused by event stream acknowledgement issues within our HTTP execution drivers.
Our executor service, which invokes functions and handles responses from the SDK, encountered an issue with invalid waitForEvent matching expressions. The responses in the system are handled via a message stream and the invalid expressions caused an error which resulted in these specific messages to nack (not acknowledge). This is expected behaviour. However, due to ack/nack policies and how our underlying message broker handles acknowledgements, all messages during a 15 minute window were relayed regardless of whether each were acked or nacked.
This caused extra load on several services: the step processing handlers; the pause/resume service which handles waitForEvent matching; cancellation matching; and the executor.
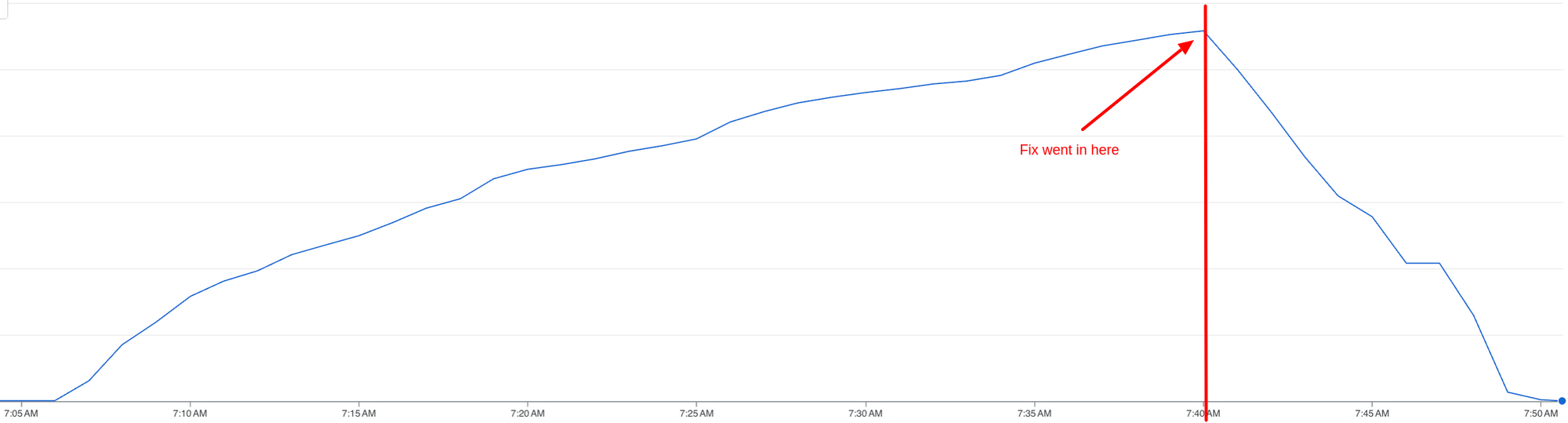 The step backlog grew until our fix went in
The step backlog grew until our fix went in
Shortly after being alerted to the backlog and errors, we introduced mitigations to fail functions when receiving invalid waitForEvent expressions. This alleviated the root cause. Once deployed, over the span of the next 36 hours we deployed code to improve the efficiency of the pause/resume service, and to improve how we handle repeated messages of successful steps.
This also helps us better deal with increased load and usage we’ve experienced over the last few months.
We apologize for the delays in processing and any issues caused during the time period with functions. We’ve taken remediations to ensure this can never happen again, and have detailed future plans for simplifying infrastructure and execution to mitigate future issues. Increased volume in our systems will not cause this class of issues for our users.
Background: waitForEvent
Inngest allows developers to build workflows in code triggered by events. One of our unique features allows you to pause functions until another specific event is received:
inngest.createFunction({ name: "Onboarding flow" },{ event: "auth/user.created" }, // The event that causes this function to runasync ({ event, step }) => {await step.run("Send welcome email", () => { sendEmail() });// Wait for the 'app/function.created' event that has the same user ID// for up to 24 hours.const fn = await step.waitForEvent("app/function.created",{if: "async.data.user_id == event.data.user_id",timeout: "24h",});if (fn === null) {// The user didn't create a function within 24 hours. Follow up.});
This allows you to orchestrate complex functionality without worrying about state, queues, or crons. The function automatically pauses when the waitForEvent step is called, and is resumed whenever a matching event is received or the timeout occurs.
Whenever you invoke step.waitForEvent, a few things happen:
- Your function pauses in execution. Inngest records this pause and initiates the timeout period.
- Inngest creates a temporary trigger with any matching statement.
- Inngest attempts to match this temporary trigger for all incoming events sent.
There’s a lot of work under the hood to make this seamless for users.
To match on the event, Inngest’s expressions currently use the cel-go library. It’s fast, and importantly it’s not turing complete: you can’t write a program in the if-expression. This is important in keeping our service speedy.
One downside is that users can write an invalid expression in the if statement. Inngest should mark the step as permanently failed with an invalid expression — it’s safer that way, as we can’t continue the function with any confidence.
Function cancellation
Using Inngest, you can also automatically cancel functions any time that specific events are received. This allows you to declaratively manage your functions:
inngest.createFunction({name: "Trial management",cancelOn: [// Automatically cancel this function if the account upgrades.{event: "billing/user.upgraded",if: "async.data.account_id == event.data.acocunt_id",},],},{ event: "auth/user.created" }, // The event that causes this function to runasync ({ event, step }) => {await step.sleep("7d"); // Sleep for 7 days// If the user upgrades, this function is cancelled and the next step// will never run.await step.run("Process trial cancellation", () =>// ...});});
Cancellation signals also relies on similar logic to step.waitForEvent, but instead of resuming functions they, well, cancel them.
We need to sample events received by our system with all waitForEvent signals that have been set up. It’s a lot of work, and in order to handle things correctly we push events into our internal queues for processing.
Incident timeline and response
- Thurs 07:06 PDT: The team was paged because of a backlog growing. Investigation discovered error rates increasing for invalid expressions in the async driver service. This caused messages to be nacked. The immediate resolution is to ignore these errors, as nothing can be done.
- Thurs 07:28 PDT: A hotfix is pushed written and the production rollout begins. The hotfix mitigates nacks and fail functions on invalid expressions immediately, rather than via nacks and a DLQ
- Thurs 07:40 PDT: Nacks stop publishing, and the backlog starts to decrease
- Thurs 07:50 PDT: The backlog is reduced to zero
While monitoring the rollout, we also noticed large areas of improvement due to cascading effects of load and this particular issue:
- Step idempotency was made stricter at 07:40 PDT, ensuring that repeated acks and success messages are handled silently.
- As the backlog for waitForEvents and cancellation continued to grow, we scaled our cluster to 25 machines to handle the backlog.
- We introduced code to garbage collect invalid and expired waitForEvent signals — something that was on the roadmap but not immediate priority.
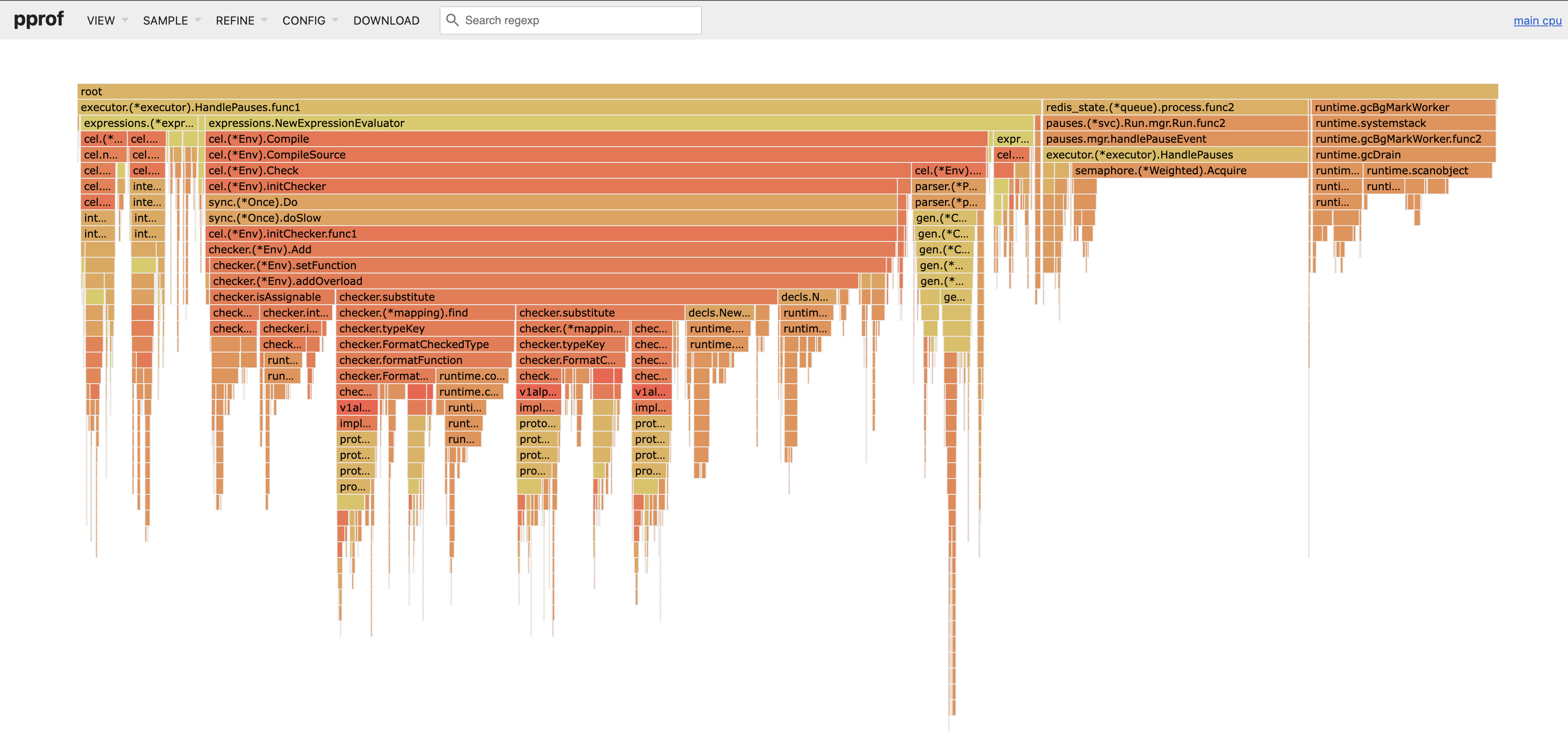
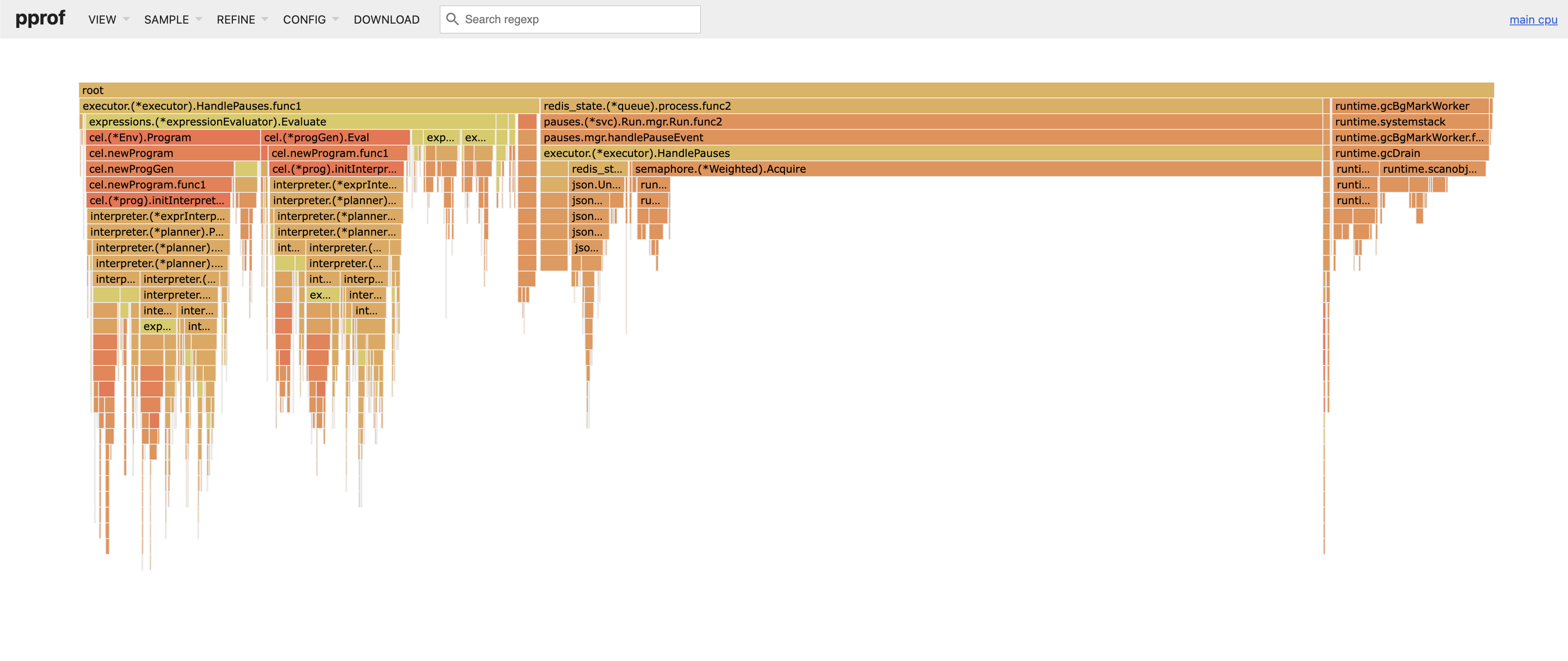
- We also introduced expression caching to lower the CPU usage when matching on 250k expressions per event.
Before expression caching:
After expression caching:
Future mitigations and product improvements
We’ve also taken the time to re-evaluate our product architecture, including everything from infrastructure to deploys to application code.
We’re currently planning several things to improve transparency into the system:
- More real-time metrics on cancellation, pauses, etc
- Improved integration tests with fault injection in message streams
- An improved history timeline to show the events that cancelled functions, and links to events matching waitForEvent
- Logging and audits for every event to show processing time for functions, waitForEvent pauses, and cancellations
- The ability to see the number of events in the backlog for new function runs and for waitForEvent/cancellation pauses
- An improved architecture and infrastructure for our executors, removing the need for message brokers to be used when handling steps. This is an internal milestone which has huge benefits for reliability.
Downtime is never something to be taken lightly and your critical workflows demand reliability. This shouldn't happen, and we will continue to improve Inngest to make sure that situations such as this do not happen. Thanks again for your patience and understanding — it’s appreciated, and we’re looking forward to being here for you for years to come.